「急ですが来週アメリカに来てロボットやりませんか」と言われてロボット開発してきた話
プロローグ的な
2月のある木曜日、アメリカに進出した日本の某ベンチャーの CEO と話す中で、「急ですが来週サンフランシスコに来て1週間ロボットをやりませんか」と誘っていただき、3日後にアメリカに飛び、丸一週間ロボット開発をしてきました。
突然の5日間の有給取得、航空券等の費用は自費で、宿泊だけ助けていただく形の弾丸サンフランシスコ合宿でした。幸い仕事は都合がつきましたが、巨額の出費とプライベートへの影響も避けられない中、我ながら思い切った行動でした。
元々多少の行動力はある方ですが、さすがに「来週アメリカに来て開発する?」と言われて即OKするほどのフッ軽ではなく、自身にとってもチャンスと考えての決断でした。具体的には、
- 前々から関心のあったロボット領域の開発に触れられる
- 短期間とはいえ有名な起業家のCEOと近い距離で働ける
- 日本ベンチャーのアメリカ挑戦の現場を見られる
- これまで触れたことのないシリコンバレーの熱を感じられる
等、自身にとって大きなプラスになると感じました。
もちろん先方の文脈としては採用活動の一環であり、私は言うなれば無給の一週間インターン、というイメージでしょうか。仕事の強度が合うか、会社とカルチャーが合うか、などを実際の1週間の開発を通して互いに見極めるプロセスです。
私はロボットへの関心とアメリカで働きたい思いはあっても転職活動中ではなく、話しの中で挑戦したい思いを強くしての急展開でした。 結果として転職しない意思決定をしましたが、短期間ながら多くの刺激を得て学ばせていただきました。一部はすでにブログとして書いていますが、ロボット開発についての学び・考えを書きたいと思います。
現地で関わった方には非常に良くしていただけましたし、大変感謝しております。
ロボット開発
ロボット開発といっても私はソフトウェアエンジニアであり、開発はロボットのソフトウェアを書くことです。 工具を使ってロボット部品を組み立てたわけでもなく、開発言語も C++ と Python なので、全く馴染みがない言語でもありません。 (ちなみに開発以外に家具の組み立てとかオフィスの設営も手伝いました。「なんでもやる」のはスタートアップらしいですね)
普段の開発と違うのは、ソフトウェアのデプロイ先がクラウドではなく物理的なロボットであり、プログラムはメモリ上の電気ではなくハードウェアを動かしているということです。
そもそも私は、何がどうなってヒューマノイドロボットが動くのか、事前知識はありませんでした。「アメリカ、行きます」と言った時点では、シミュレーション環境で高速に強化学習を回すことでヒューマノイド含むロボット領域の進化が加速していること、学習しているのは関節のモーターの数値であるくらいの認識しかありませんでした。
大学院で深層学習を研究しており、強化学習も簡単に触ったこともありましたが、ロボット・ロボティクスは全くの未経験、素人です。
AI による知の高速道路
一週間の短い時間で最大限の学びを得る(&採用候補者としてアピールする)ため、渡米前の2日で予習をすることにしました。 参考書を買って読んでも超短期的には間に合わないので、(当然) AI を使ってのキャッチアップを試みました。
有名論文のリストアップ、素人が理解しやすいようなスライド化、基礎知識のインプットと疑問の解決、全てを AI で行いました。 ベースが 0 なので付け焼き刃の表面的知識でもドメインへの理解は雲泥の差となりました。
知識だけでなく手触り感も得るため、"Unitree" の強化学習のレポジトリを動かしました。 4年前に「そのうち AI をローカルで回したくなるかも」と調達した自作 PC と GPU が役に立ちました。 (いつどこで何が役に立つかわかりませんね)
https://github.com/unitreerobotics/unitree_rl_mjlab
Unitree とは世界のヒューマノイドロボット領域のトップ企業の一つの中国企業です(それも今回初めて知りましたが)。 このレポジトリは Unitree が販売しているヒューマノイドロボット "G1" をシミュレーション環境で動かして学習させるサンプルレポジトリです。 渡米直前までパラメータ調整を頑張って、フラフラしながら直進することはできるようになりました。
2 日でもある程度のインプットができたのは、間違いなく AI のおかげでした。 まさに ChatGPT が出てきた頃に言われていた知の高速道路です。 裏を返せば、専門違いの領域へのチャレンジも、キャッチアップのマインドと馬力さえあればハードルはかつてないほど低く、非現実的ではないと感じました。 実際ロボティクスでいえば、 SO101 (数万円で試せるロボットアーム)で趣味でちょっとしたロボット開発をするソフトウェアエンジニアが増えていると感じます。
もちろん経験と現場で得られるドメイン理解はそれぞれに深さがあり、AI 以上の専門性を手に入れるのは至難の業ですが、少なくともスタートラインには立ちやすいはずです。
いざ実践へ
渡米して私が動かしたのは、 Booster K1 という中学生くらいのサイズのヒューマノイドロボットです。
https://www.booster.tech/booster-k1/
先に述べたようにスクラッチでC言語で制御処理を書くわけではなく、制御をある程度抽象化した SDK を使います。 あらかじめプログラムされた基本的な挙動(手を挙げる、両手を挙げる、等)も API で呼び出すことが可能です。 また、関節のパラメータ(位置や角度)も API で取得可能なので、センサーへの接続を自分で実装などもしません。
K1 含め、多くのヒューマノイドロボットにはコントローラーが付属しており、デフォルトで歩かせたり踊らせることが可能です。 ジョイスティックを倒したらその方向にしっかり歩くというのはそれだけで感動です。 子供の頃に ASIMO がノロノロ歩くのをみた記憶が蘇り、その時との違いから飛躍的な進歩を感じました。(実際にはソフトウェア技術だけでなく、部品が安価に量産可能になったことで中小企業でも入手可能になったことも進歩の一つです。)
コントローターや API でデフォルトの動きは呼び出せますが、タスクは愚か、腕を好きな方向に動かすのも一苦労です。 一週間でできたのは、
- ロボットの腕の動きを記録可能な状態にする
- 人間が腕を動かす
- 記録された動きを API 経由で再現させる
というものでした。ヒューマノイドロボットにおいては初歩的なタスクですが、苦労しました。
ソフトウェアエンジニアリングやウェブアプリケーションの世界ではグーグル検索やコードリーディングでアクセス可能な情報を辿れば大体の問題が解決しますが、ロボットではそうはいきません。 ヒューマノイドロボット自体がまだ黎明期で、エコシステムはまだ未成熟。
Unitree の G1 が広く使われていますが、まだまだ各社がしのぎを削ってデファクトが定まっているわけでもありません。 情報は全く整っておらず、実際 K1 はドキュメントの記載に古い箇所があったり、同シリーズのグレードによる違いがドキュメントに反映されていませんでした。
SDK があると言っても内部の制御詳細は非公開で、エラーに詳細なスタックトレースもつきません。 プレイヤーが少ないのもあって、trial & error がネットでは見つかりません(そもそも高いロボットを買える企業は限られます)。 さらに、固有パラメータを持つハードウェアが絡むことで、再現性が低下し、問題の複雑性も増します。
結局、前の記事に書いたように、何か壁に当たったら(以前の記事に書いた)「開発企業の人に聞く」ことが最適解となります。 (困っていた問題について直接答えを聞いた後でも、それが解であることは公開コードからは読み取れませんでした。)
ロボット、あるいはヒューマノイドロボット業界について
ロボット開発の難しかった点を書きましたが、開発自体は全くもって辛くはなく、非常に楽しい時間でした。
新しいものを学ぶことが元々好きでもありますし、自分が書いたコードでロボットが動くのは、 hello world を初めて表示した時と同じ感動があります。
そんなワクワクするロボット開発ですが、スタートアップのような速度感で、ソフトウェアエンジニアが未経験から挑戦できる機会は貴重です。 構造的に費用と環境の問題があるからです。
前述のように、ロボットは始めるだけでも大きなお金がいります。 どこから何を買うかにもよりますが、booster K1 も100万前後、 Unitree の G1 も数百万かかるそうです。 Web サービスやアプリと違ってまずハードウェアを買う必要があり、それは多くのの日本のスタートアップにとっては回収の見込みも薄い高額な初期費用です。
フィジカルAI がバズワード化しているとはいえ、ヒューマノイドロボットはまだ利益を生むかは未知数で、0から始めるにはリスクマネーが必要です。 キャッシュに余裕が必要となると、プレイヤーは大きな企業に限られてきます。
一方、大きな企業であればステークホルダーが多く、動きは遅く、保守的になりやすいです。 そうなると、外部から未経験の人材をそれなりの給料で雇うことは非常に難しいですし、仮に採用されても高速に PDCA を回すことはまた並並ならぬソフトスキルを必要とします。
ロボット、Bet するかどうか
フィジカル AI は注目を浴びて資金を集めていますが、まだ確証はありません。 個人的に、ロボットがいずれ人間の仕事を代替し、世界中に溢れていくのは確実だと考えていますが、一方でそれがいつなのかはわかりません。 世界に溢れるロボットがヒューマノイドロボットとも限りません。
巨大な資本が動いている中で、求められるのがロボット開発なのか、ロボットをデプロイするスキル(ロボット版FDE)なのか、それともセールスなのか。 帰国してから色々な情報を仕入れるようになりましたが、今でもわかりません。 まだ何もかもたりません。
そうは言っても、10 年先には世界がロボットで溢れていることは間違いなく、今から何らかの形で関わっておくのはキャリア視点で良いと思いますし、物理的にロボットを触ることが楽しくてワクワクするなら、是非もありません。 (じゃぁなんで転職しないねん、というツッコミはすみません、まだうまく語れないのでぼかしておきます。会社の人に話しても「話を聞いてるとおまえはロボットやりたそうに見えるけどね」と言われます。)
今回のサンフランシスコは色々な刺激を受け、特に多くの起業経験者と話す中で自分で事業をやりたい、起業したいという思いも芽生えてきました。諦めかけていたアメリカで働きたいという思いも再燃してきました。 現職でもまだまだやりたいことがあります。現職も頑張りつついろいろな人と話し、課題とチャンスを探したいと考えています。
(今回お世話になった CEO には、記事にすることについて口頭で許可をいただいています。
Meta Ray-Ban Display のデモ体験をした。未来を感じた
一週間サンフランシスコに行ってきました。
世界の技術の最先端が生まれる場所の熱気はすごく、面白いものもたくさんありました。その一つを紹介します。
Meta Ray-Ban のサングラスは、数年前から持っている人はいて、昨年 2025/9 ごろにその第二世代とともに発表されたのが Meta Ray-Ban Display です。
2026/02/27 現在、アメリカでしか発売されておらず、購入には店頭でのデモ体験が必要(メガネや腕のバンドのサイズ調整のため)という、少し購入へのハードルがあるプロダクトです。 まぁお値段が $875 なので、オンラインでポチッとしやすい金額ではないのです。日本人からすると、ドル表示の方が感覚が麻痺って支払いやすいかもしれませんが、14万円くらいですw
さて、デモ体験をした際に、これはすごい、SF や未来の世界だと感動したので、感動を少しお裾分けしたいと思います。
第一世代
先に Ray-Ban Meta の話をします。これは知っている人は飛ばしてください。数年前に発売されているので試したり買った人も多いかと思います。
Ray-Ban Meta は、Ray-Ban (サングラスが有名) のサングラスにカメラと AI スピーカーがついたものです。 サングラスをかけて「Hey Meta! 写真を撮って」と言えば、サングラスについたカメラが今みている視界を撮影してくれます。 動画も撮れます。
ハンズフリーで撮影・録画できるのは手が塞がっている時に便利ですし、電話したり音楽を聴いたりもできる、そんなガジェットです。
私は買った人に見せてもらっただけですが、正直普段そんなに写真撮らないですし、日常使いするイメージもわかず、おもちゃという印象でした。実際に持っているわけではないので、間違いがあったら教えてください。
新発表のうち、 Display じゃないやつ
そんな Ray-Ban Meta の Gen 2 が発表されました。
機能差分はちゃんと調べてないのですが、昨今の AI の発展で音声認識の精度があがったりといった強みがあるのだと思います。 SDK も発表されており、カメラのデータをスマホで表示できるようです。
カメラや録画の性能もあがったことと思います。
Meta Ray-Ban Display がやばい
いよいよ本題です。Meta Ray-Ban Display は、Ray-Ban Metaの機能に加えて、グラスの右のレンズに特殊なディスプレイがついていて、かけると空中に小さい画面が浮かんで見えます。 外からみてもディスプレイを見ていることはわからないのも面白いです。
実は私が驚いたのはディスプレイではなく操作インターフェースとその体験です。 手首にリストバンドを巻いて、ハンドジェスチャーをEMS (電気刺激) で読み取って操作します。手をグーで握って親指をスライドするのが上下左右、OK サインを作る動きがクリック、といった具合です。 この技術自体は昔からあったそうですが、それをプロダクトに統合して、視界のディスプレイ上を驚くほどスムーズに操作できるのは感動でした。
Display があることで何が嬉しいかというと、まずチャットができます。 入力は音声入力になりますが、簡単なメッセージ確認・返信ならスマホを開かずに完結させられます。 また、撮った写真を確認してチャットでシェアすることも可能です。チャットアプリは現在は Meta エコシステムの Messanger / WhatApp / Instagram に限られていました。
AI 機能もついており、 AI との会話をチャット風に確認することもできます。 Display がついていない Ray-Ban Meta では音声会話しかできないのが地味に使いにくかったですが、その点は Display では不便を感じませんでした。もう一つAI 機能の目玉でもあるのがリアルタイム文字起こしで、話している人の方を見るとディスプレイに英語が書き起こされてきます。英語リスニングが苦手な人や、人の話をうっかり聞き逃す人にはとても便利だと思いました。海外カンファレンスで使いたい。
ここまで文章のみでよくわからんという人は TBS が 1分未満でまとめてくれてるのでご視聴ください。
一緒にいた人に聞いたところ、このメガネのことを知らなければ、相手が Display を見ているとは気づかないくらいのようです。 知ってる人なら、自分が Display を見ている時に相手に焦点があってないように思うとのこと。 これなら上司に怒られている時にチャットやカメラロールを確認できますし、怒られているから虚な目をしていると思ってもらえそうです。
あと余談ですが、レンズがデフォルトで偏光グラスになっていて、明るい外では自動でサングラスになるのが個人的にはありがたいです。
とにかく未来を感じた
私の文章力のなさも相まって、おそらく感動を20% も伝えられていないと思うのですが、ハンズフリーでチャットを操作でき、画面もあるのは、衝撃的な体験でした。 普段腕が2本だと足りないと感じている私は、スマホの機能の一部を代替するものに感じました。
さらに、OpenClaw と繋げれば日常のいかなる場面でもチャット経由で開発できるじゃん、と思ったら実際にやっている人がいました。
I’m building apps directly from my glasses 🤯
— Jake Ledner (@jake_ledner) 2026年2月19日
OpenClaw + Meta Ray-Ban Display pic.twitter.com/0WtBJ85gAK
その後とか今後
日本だと静かな場所で声を出すわけにはいかないので、音声以外のインターフェースはどうかと思っていましたが、CES で発表されていました。
指でアルファベットを書けば反映されるという仕組みです。さすがに大変だとは思いますが、緊急手段としては使えそうです( "K" とちゃっと返信するくらい) 同時に発表されている機能も面白くて、グラスのディスプレイにカンペを表示してくれます。顔と視線は聴衆に向けながら、プレゼンのカンペを読めます。これも素晴らしい。
日本は盗撮やらなんやらの懸念で発売は当分先になるだろうと思っています。あとは視力への影響とかは未知数だと思います。ともあれ、早く出てほしいです。 グーグルもスマートグラスを出すらしいですし、2026 はスマートグラスかロボットの年になるのではと予想しています。
アメリカに行かれる方は waymo とともに Meta Ray-Ban Display も体験してみてください。
肌で感じたシリコンバレーのコミュニティーの強さ
一週間サンフランシスコに行ってきました。 サンフランシスコを訪れるのは9年前の旅行以来の二回目で、前回は一人旅で街並みを楽しんだり Stanford やら Google のオフィスを観光したのですが、今回は現地進出している日本スタートアップにお世話になり、色々な人と話す中でシリコンバレーの空気をかすかに感じました、という話です。
お断り:
- サンフランシスコの市内(SoMa というのかな)にずっといたので、Palo Alto, San Jose の方には入っておらず、タイトルは主語がでかいですが、過度な一般化ではないと思って書いています。
- この文章は飛行機の中という都合上、真心こめて人の手で書いてます。たまには読みにくい文章を読んでください。
シリコンバレーという環境
個人的な意見ですが、あらゆる文脈における成長において、環境は非常に重要な変数です。同じ志、同じ行動力を持っていても、環境が違えば結果が違います。 世界で見ても圧倒的な数のスタートアップを生み出すシリコンバレーにはもちろん人と金が集まってきますが、無数のスタートアップが現地で形成する独特なコミュニティも、スタートアップの速度と成功に寄与していることを感じました。
そういえば、日本のとある VC が「シリコンバレーのようなスタートアップコミュニティを作りたい」と言っていた記憶があります。当時は実際それがどういうものかはあまりしっくりきておらず、強いて言えば
- たくさんの投資家がいるのでアイデアだけでも熱意と行動力が評価されれば資金調達が可能
- たくさんの起業家がいるので起業に対する心理的ハードルも低く、ノウハウもたくさん手に入る
- 規制が意図的に緩められており、自動運転等の最新技術が最初に目の前にデプロイされる
- 結果的にスタートアップの数が増えやすく、成功するスタートアップが生まれる
といったエコシステムのことを指している理解でいました。
起業のしやすさ
私は20代になってから「いつかは起業したい」と思いながら色々な言い訳をしてきて、未だに20万円払えばできる登記すらしたことがありません。上記のように心理的ハードルを下げてくれるシリコンバレーが近くにあったら、自分も起業できたかも、などと本気の負け惜しみを何度も考えています。 というのも、私がソフトウェアエンジニアになるきっかけとなる 10年前のカナダ留学の時も「留学行きたいな、とはいえ卒業が一年遅れるのもな...」と今のように足踏みするなか、最終的には「周りも留学しているから」とトビタテた人間で、心理的ハードルを下げて生まれるスタートアップは実際小さくはないと思っています。(行動した結果、新しい世界が見えて楽しくなる経験をしても、踏み出せないでいます)
ともかく、大局でみれば、起業が当たり前に選択肢としてそこにあることは、成功するスタートアップを生み出す上では大事なことだと思います。
ここまでは日本でも考えてはいて、現地で新たに気付いたのは、例えば散歩をすれば Github やら Cloudflare やら、名だたる大企業のオフィスが目に入ることです。そこを目指していなくても自然と見つかるくらい密集しています。Google 等の Big Tech になれば巨大なオフィスを持ちますが、この企業のオフィスは意外とこんな小さいのか、威圧感ないな、と思ったりします。サンフランシスコは東京のように超高層ビルが延々と並んでいるわけでもないので、普通に2階建のビルに私でも知っているサービスのロゴがついています。 そうするとなんだか、神格化された雲の上の企業ではなく、急に親近感が湧いてきます。自分でもできそう、とは言いませんが、「得体のしれない何か」ではなくなるというのは踏み出しやすさに効いてきます。
これだけ密集していると、イベントもあります。現地で教えてもらったのですが、 luma という特に tech 関連の meetup イベントに強いアプリがあり、そこで Founders & Investors というイベントを見つけて行きました。私は Founder ではありませんが、(コーヒーもらえるし、)Founder 志望のフリをして参加しました。集まった30人超えのほとんどが Founder で Investor はゼロ、という悲しいオチはあったんですが、Founder 同士でも話は十分に盛り上がっていました。私は 4,5 人と話をしたくらいであまりに自分の提供できるものがない恥ずかしさに耐えられなくなって途中で帰りましたが、それでも色々な話を聞けました。大変失礼ながら「そんなアイデアで大丈夫?」と思うアイデアもありましたが、それでも真剣に楽しそうに語る姿を見られ、熱気も感じました。起業志望でもスタートアップでもなく"起業家" 向けに絞ったイベントでも実際にたくさんの人数が集まるのは、やはり母数の大きさを物語っています。
書いていて、この章はなんだか「ほらね、シリコンバレーだったら私も起業できたよ」と自分を正当化したいがための内容な気もしてきました。それでも参考になれば幸いです。
スタートアップ同士の距離の近さ
サンフランシスコのスタートアップは互いに物理的にも心理的にも距離が近かったです。
私がお邪魔していたスタートアップには、まだ人数規模が小さいのはありつつも、多種多様なバックグラウンドの人がオフィスにフラッと遊びにきて、業界の話をしたり、自分の会社に勧誘したりします。(もちろん本当に遊びにきているのではなく、"確固たる目的があるわけではないけど好奇心や情報交換のために訪問する" という意味です) もちろん日本でも、同じシェアオフィスに入っていて仲良くなって、というのがあるのかもしれませんが、エンプラのお客さんを抱えているような中規模な会社でもそういったことが日常的に行われているようで、強く印象に残りました。
物理的にも距離が近いのも侮れません。顔見知りのエンジニアに偶然道であって、「最近どう?」から情報交換したり「オフィスくる?」と話が発展する。隣の部屋の会社と「初めまして、何やってんの?」から「投資家紹介してよ」と人伝に機会が生まれたりする。こういった偶発的な出会いはバーチャルオフィス、フルリモートの会社では生み出せません。だからフルリモートはダメ、物理だ、という話ではなく、むしろ物理的な近さを競争力に変えられる方が特殊でとてつもない環境だと思います。そこにいる人は全員チャレンジャーであり、その熱気の高い人々が物理的に近い距離に密集するからこそ生まれる化学反応なんだと思います。
問題解決の速さ
スタートアップがチャレンジするビジネスは最先端です。最新技術を使っていれば、頻繁に技術的困難にぶち当たります。特にシリコンバレーとなれば最先端も最先端です。昨日発表の技術を今日試すのではなく、さっき発表した技術は中の人から事前に聞いていて、発表されたら数時間後には試すくらいの差です。まぁこれ自体は「ふーん、別に翌日試すでもよくね、優先順位ってあるでしょ」という感じです。
特筆すべきは、その速度ゆえもあって、「困ったら知っている人・詳しい人に直接聞く」「聞かれたら喜んで助ける」行動が定着していることです。困ったときの相談は報連相の一つですが、それでもググって色々試したり、ドキュメントやソースコードを読んでなんとか糸口を探そうとしたりを考えるものです。しかし誰も触ったことがない発表直後の技術であれば、当然ググってもトラブルシューティング情報は出ませんし、ドキュメントも間違いが多く、ドキュメント自体がないこともあります。その時に、「あいつが詳しいからサッと聞いてみよう」とチャットします。そもそも事前に話が聞けるくらいの関係性があるのは前提としてありつつ、やはり餅は餅屋で、困りごとにドンピシャな回答が返ってきます。
課題解決において専門家にさっと聞くことの重要性は確かにビジネス本に書かれていますが、それが高い次元で行われていて、かつ上記の物理的近さも寄与する事前の関係性構築ができていると、「なんならこっち来て教えてよ」「今度ちょっと話そうよ」と発展します。
そんな形で、直接の競合でなければ互いに切磋琢磨するライバルであり、一緒に頑張る仲間であり、困ったら互いに助け合っていく、そういう空気感がありました。なんなら競合であっても構わず仲良くやってそうです。 情報が民主化されて AI でアクセスが高速になってもなお、物理的な距離と競い合いに近い互助精神に支えられたコミュニティがスピードの好循環を生み例外的な速度を生み出していると感じました。
おわりに
たった一週間しかいなかったし実際にそこに就職したわけではないので、勝手に補完して勘違いしていることもあるかもしれません。また、もちろん書けないこともあるので多少ぼかしたりもしましたが、シリコンバレー賛美ありきで誇張して書いたりなどはしていないつもりです。 実際、日本が、東京が、こうなれるとは思いません。東京がシリコンバレーのようになれば私は楽しいですが、そうなった方が良いか・できるかは別の議論で、私はそこを積極的に議論したいわけでもありません。(そもそも私が知らないだけで既に東京の一部でこういう世界があるのかもしれません)。あくまで一個人の、一週間の感想でした。
OpenClaw その2 Discord と繋いでみる
OpenClaw を始めてみました。
OpenClaw のチャット機能上で discord channel への投稿は可能になりましたが、discord channel から OpenClaw の bot に呼びかけても反応がありません。

discord channel からでも OpenClaw の bot と話せるようにするまでにやったことを解説します。
discord channel から OpenClaw の bot と話せるようにする設定
discord 側設定
OpenClaw の公式の document を読んで、discord 上の bot の設定をします
discord の Developer Portal から、アプリの "bot" 画面 ( https://discord.com/developers/applications/<bot_id>/bot
) を開きます。
- Message Content Intent
- (必要なら)Server Members Intent
以上二つを ON にします。

アプリを install した時と同じ手順 (サイドバーから "install" を選択) で再度をアプリを install します。
openclaw 側設定
update
openclaw は最新版にしておきます。
openclaw update
update したら、 doctor コマンドでセキュリティの問題等を確認しておきます。
openclaw doctor
設定書き換え
~/.openclaw/openclaw.json を書き換えていきます。
guild と channel (discord の server のこと) を指定する。bot が招待されている環境では全てのメッセージを読み取れる状態にします。
discord の userID は、discord を一時的に開発者モードにした上で、自分のアイコンを右クリックで取得できます。(もっとスマートな取得方法もありそう)
以上を設定すると、以下のようになります。
{
...
"channels": {
"discord": {
"enabled": true,
"token": "xxxx",
"groupPolicy": "open",
"guilds": {
"xxxxx": {
"channels": {
"yyyy": {
"requireMention": false,
"users": ["zzzzz"]
}
}
}
}
}
},
...
}
今回私は bot だけしかいないチャンネルを作っていますが、複数人と会話するチャンネルでは、 requireMention: true を設定してメンションしたときしか反応しないようにしておくと良さそうです。
その他の補足として細かい設定事項はありますが、ケースバイケースなので、OpenClaw の公式の document をご参照ください。
結果どうなったか

mise の task 機能の auto completion / suggest を効かせる
先日、自分の PC で mise を使い始めた話を書いた。
便利だったので、本格的に色々なPC環境で mise を使い始めている中で、一部で mise run (mise のタスク機能) の自動補完が効かないことに気づいた。
微妙な環境の差異やほかツールとの干渉でうまく動かないこともあるので、改めて設定し、方法を整理した。
結論
~/.zshrc ないし適切なファイルに
# zsh auto completion autoload -Uz compinit && compinit # mise eval "$(~/.local/bin/mise activate zsh)" eval "$(~/.local/bin/mise completion zsh)"
を書く。
私の場合は以下のエラーも出た。
Error: usage CLI not found. This is required for completions to work in mise. See https://usage.jdx.dev for more information.
mies task を利用する必要な人だけ追加で install してほしいライブラリということなのだろう
% mise use -g usage
これで無事に suggest されるようになった。
例えば mise run から tab キーを二連打すると以下のように、自分で設定したタスクが suggest されるようになる
% mise r lint -- コードの静的解析を実行 setup -- 開発環境の初期セットアップ
初めての Raspberry Pi 5 と初めての OpenClaw
先日 OpenClaw (当時 Clawdbot / 旧 Moltbot ) が話題になり、同時にセキュリティ面では最高水準のリスクだとも話題になった。
セキュリティを気にするのであれば環境ごと分離してしまえばいいではないか、ということで専用の Mac mini を用意して動かす人も散見された。
OpenClaw を動かしたいが、セキュリティ的にヤバいものを自分のPCで動かすわけにはいかないし、かといって Mac mini なんて持ってなくて、買うには高いし、と悩んでいる中で「ラズパイでも動かせるぞ」という話を耳にし、試してみることにした。
買ったもの
Raspberry Pi を自分で買って動かすのは初めてで、 Deep Research を駆使しながら必要な部品を調べて以下を購入した。
- Raspberry Pi 5
- Raspberry Pi 5用 公式クーラー
- Raspberry Pi 5用シンプルケース
- 5.1 V Raspberry Pi 5用 AC アダプター
- 絶対 5.1 V じゃないとダメ、という話を AI が教えてくれたので、公式のアダプターを選択。
- microHDMI ケーブル
- microSD
- SSD と迷ったが、OS を入れるのがメインの役割だし、お金のかけどころではないと判断し、我慢。

総額 ¥25,000 ほど。(買ったことはないが、)昔の 2倍くらいにあがってないか...?
余談だが、1月中旬に Raspberry Pi にも値上げの波が来て、 ¥14,000 -> ¥20,000 くらいになったらしい。私は AI が探してくれて ¥14,000 を買えたが、在庫限りのようなので購入検討の方はお早めに。
Raspberry Pi 組み立て・設定
OS 準備
私のようにあまり知らない方に補足をすると、Raspberry Pi は小さな PC の OS がないバージョン(ハードウェアがある)で、動かす際には OS (Raspberry Pi 用OS) をいい感じに書き込んだ microSD を本体に挿した状態で起動する。(ここで microSD ではなく SSD にしておけば起動が数秒〜十数秒早くなったりする。)
OS を microSD にいい感じに書き込むにはどうすればいいかというと、 Raspberry Pi 公式の Imager というツールを使えばよい。
Raspberry Pi software – Raspberry Pi
正直 OS の準備は不安があったが、sandisk の microSD がしばらく認識されずに戸惑った*1くらいで、想定よりずっとスムーズに進められた。
OS 書き込み時にいくつか入力項目はあったが、特に迷うことはなかった。 ssh も設定できたので、ssh で作業したい人は作業 PC の公開鍵を入れておくと楽。 WiFi 設定も入力したが、(間違えていたのかなんなのか、)Raspberry Pi 起動後に自動では繋がらず、結局もう一回入れることになった。
組み立て
組み立ては以下の youtube 動画を参考にした(組み立て部分のみ)
https://www.youtube.com/watch?v=ND1ybCH2Pcw
クーラーのコネクタは接続の上下がわからなかったが、一応動画と同じ色の順番で、はまりもしたので、良いとした。きっと親切設計だろう。
ケースは段ボールみたいな板が3枚で、買い間違えたかと思ったが、アクリル板の表面に段ボールっぽいシールが貼られていて、剥がせば良かったらしい。...ということを説明書で理解した。シールは水で濡らさないと剥がせなかった。
説明書: https://www.kyohritsu.com/eclib/PROD/MANUAL/kpsb616.pdf
できあがったものがこちら

こんなに小さいものが PC として動くのは感動である。
ここから microHDMI で画面に繋いで、電源とキーボーディスト繋いで、起動して、WiFi 接続した。
OpenClaw
install
ここからの作業は ssh して進めた。
まずは OpenClaw の install
curl -fsSL https://openclaw.ai/install.sh | bash
Raspberry Pi は OpenClaw 専用なので、抜かれて困る情報はなにもない。無敵だ。何も気にせず shell script を実行した。(同じネットワークにあることのリスクはあるが目をつむる)
Recommended にしたがって進めると onboarding に進むので、連携したいツール等を選択していく。今回はまずは discord を選んでみた。
ダッシュボードにアクセスする
OpenClaw には Chat 等をブラウザで行えるダッシュボード WebApp がついていた。
これを ssh 元の端末(作業端末)からもアクセスを可能な状態にするための作業を行なった。
まず、Raspberry Pi 上の .openclaw/openclaw.json ファイルを編集、 bind: "lan" に書き換える。
さらに作業端末から port forwarding
ssh -N -L (port):127.0.0.1:(port) username@192.168.x.x
Dashboard を起動したら、“トークン付き” の方の URL を開く。 Chrome ではセキュリティ機構でブロックされたので、 Safari で開けば混乱が少ないかと。
$ openclaw dashboard ... http://localhost:<port>/?token=xxxxxx

Discord と繋げてみる
Discord も普段使わないので、見様見真似だったが、 Discord で App を作り、 token 発行・専用サーバーへの招待を経て、無事 OpenClaw から Discord にポストさせることができた。
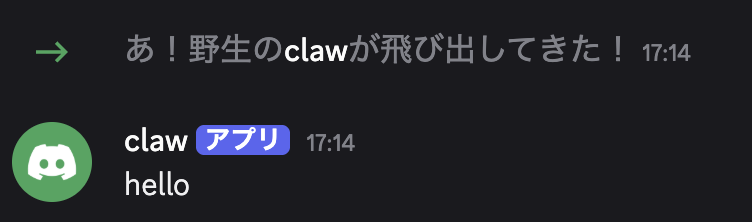
Discord チャットで指示を出して OpenClaw に反応させることはまだできていないので、実装したら記事にする予定。
おわりに
届いて動かすまでの数日で世間の話題は早くも Codex App へと移ろい、 OpenClaw の存在は過去のものとなっていそうである。恐ろしい。
結局 Chrome 拡張では ESModule が使えるのか
背景とか AI とか
たまに Chrome 拡張開発をするのだが、その度に混乱することがある。 それが ESModule を使うのか CommonJS を使うのか、ということだ。
昨今は仕事でもプライベートは基本的に ESM を使っていて、 require なんて全く見なくなった。
だから油断すると import 文を書いてしまうわけだが、 Chrome 拡張機能においては Cannot use import statement outside a module というエラーに見舞われる。もはやトラウマものである。

この件を AI や AI Editor に聞いてみると、やれ ESModule は使える、指定するファイルが悪いので直しましょうか、など言われるが、どれも検討違い。 AI に任せても今は解決するフェーズにないらしい。
おそらくだが Chrome 拡張機能に関しては "実装→結果を確認→実装を修正" というフィードバックループを回すことができず、インターネットの断片的情報だけしか学習データを持っておらず、 AI の苦手分野なのだと思う。
Gemini Pro 3 がマルチモーダルへの対応性能を見せ、 Antigravity が画面の操作を AI Feedback loop の中に持ち込めるようになったのが先月で、AI 性能はまだブラウザそのものを AI で操作する範囲に収まっており、Chrome 拡張を load して自動で開発を行うフェーズには至っていない(あるいは興味を向けられていない)
本題
AI への脱線はこれくらいにして、本題というか知識。
Chrome 拡張機能で使われる主なファイルそれぞれについて、対応しているモジュールシステムが違う
content scripts : manifest の content_scripts で静的に登録される「普通のスクリプト」であり、ページに埋め込まれるスクリプトと同様に扱われるため、 import を直接書いてもモジュールとして扱われない。
background : ESModule は利用可能。Manifest V3 から background は service worker になり、type: "module" を指定すると import/export が使えます。
popup / options の HTML : popup.html に <script type="module"> を置けば ESModule が使える。
ということで、冒頭の Cannot use import statement outside a module は content_scripts にて import 文があると発生するエラー。
さて、content scripts についても ESModule で実装した上で import 文が出ない様に webpack でバンドルすればいいじゃんという話はあるが、それは AI が答えてくれるので筆を譲ることにする。